
Building resilient agentic systems
A guide to the foundations underneath our AI agent


At Gradient Labs, our AI agent interacts with the customers of financial services companies: high-reliability is non-negotiable. Suppose you get in touch with your bank about an important problem related to your money — there’s no excuse for your bank’s AI agent not to be able to reply!
Under the hood, we use a blend of different large language models (LLMs) to construct the highest quality answers. LLMs are therefore a critical dependency for our agent, and we need to be resilient to all kinds of failures or constraints in order to provide a reliable experience. This blog post goes into some detail about how we achieve that.
AI agents are a new paradigm
When building a server which handles a request, such as a mobile phone app calling a bank, the request might return within a few hundred milliseconds. Anything which fails on the path of the request would likely result in a retry of the entire request.
In agentic systems, where a single reply may be the result of a chain of LLM calls, requests can span much longer durations. Each LLM call costs both user-facing latency and money, so you don’t want a single failure in that chain to result in the entire request being retried:
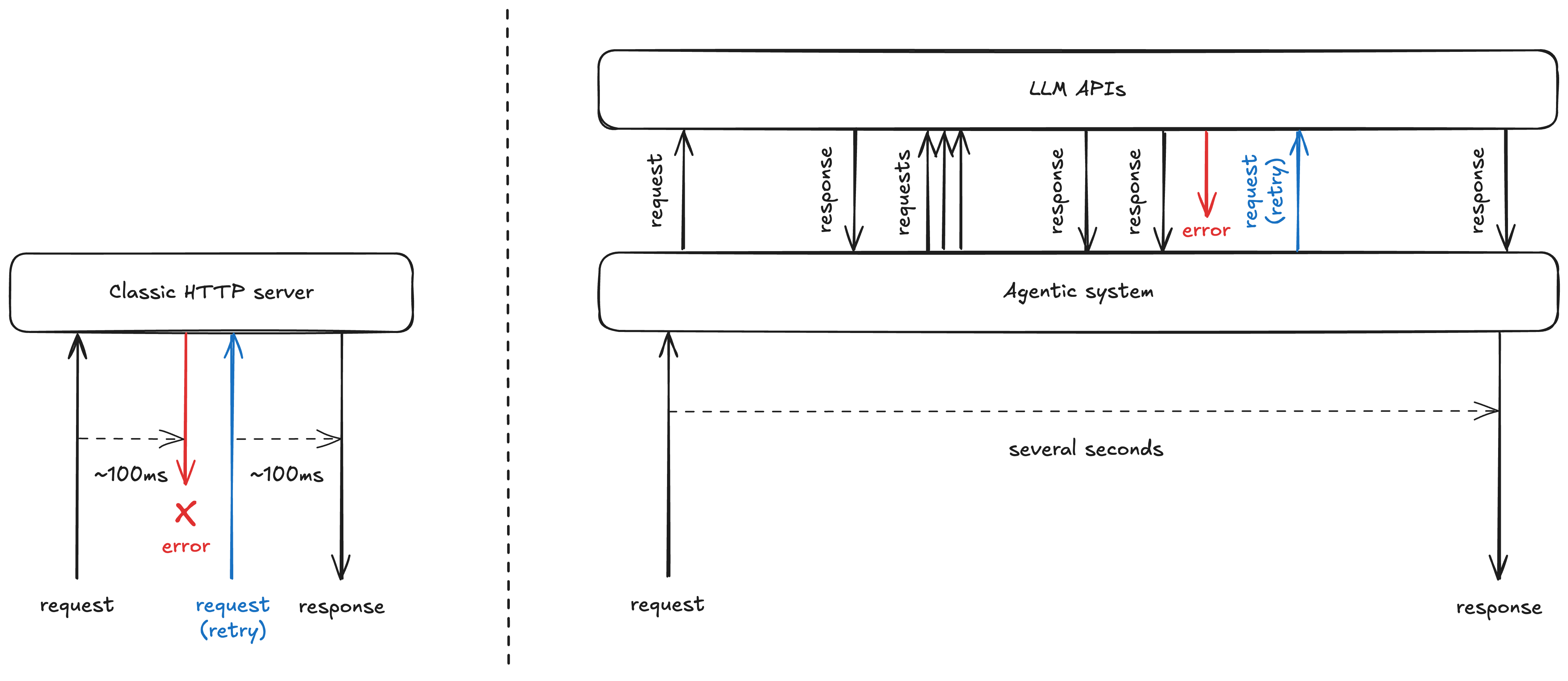
One way to solve for this might be to manually write data to a database at the end of each call, to persist state that captures the progress of your agent. This way, you can always recover from a checkpoint upon failure—if the database write succeeded. Another way might be to implement `@retry` logic at every step of your agent, which means solving for retry logic while trying to implement the AI agent. At Gradient Labs, we use Temporal, a durable execution system, that provides us with a way to effectively checkpoint progress out of the box.
Failing over across providers
The earliest design choices we made at Gradient Labs favoured an architecture that enables us to experiment with, evaluate, and adopt the best LLMs for each part of our agent. Right now, we use three major groups of models — from OpenAI, Anthropic and Google. Each of these groups of models are hosted in multiple places, giving us the ability to fail over from one place to another:
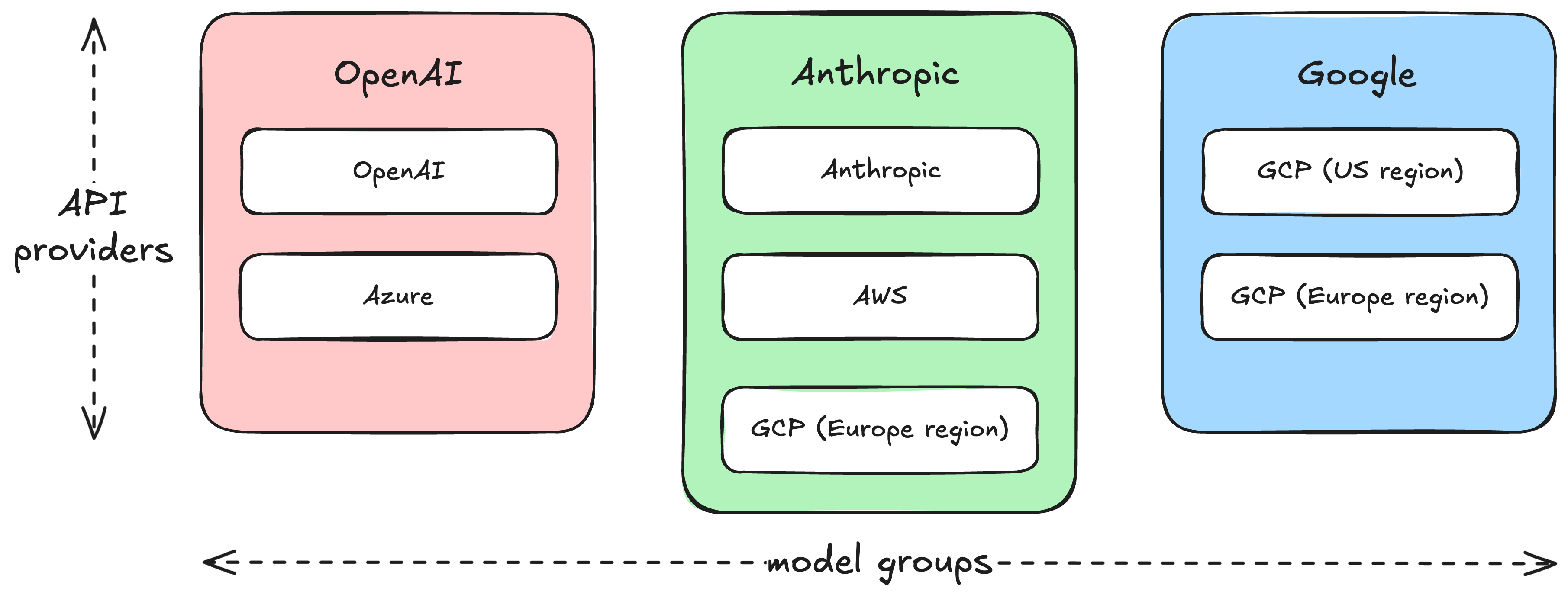
We take advantage of this to both (a) spread traffic across providers, to increase utilisation of per-provider rate-limits, and (b) fail over from one provider to another when we encounter certain errors, rate limits or latency spikes.
In our platform, each completion request starts with an ordered list of API provider preferences. For example, if we’re making a request for GPT 4.1, we might have the preference ordering: (1) OpenAI, (2) Azure. We can configure these preferences on both a global and a per-company basis, and we can also assign them proportionally to how we want to split traffic across the two. If we encounter certain types of errors, then we failover to the next provider.
The nuance of a failover system is: when is it right to fail over? We currently handle four broad categories:
Successful, invalid responses — for example, perhaps we asked the LLM to place its final decision inside
<decision>...</decision>tags, but the generated response doesn’t include these. We do not need to fail over for these.Errors — LLM APIs, much like any other software provider, can return all sorts of errors. We’ll failover when we hit most 5XX errors.
Rate limits — LLM APIs impose different rate limits for each model. Increasing these limits, particularly for more recent or experimental models, is not an automated process. If we failover due to being rate limited, then we mark the API provider that we failed-over from as “unavailable” in our cache for a short while. This way, we don’t waste latency on subsequent requests on a resource that’s already over limits.
Latency — LLMs can be slow. This is expected to be variable across calls. But we need to look out for scenarios where they’re globally slower than expected—this is a symptom that something is wrong. We currently failover if the request exceeds a timeout in the p99+ percentile of latency.
Failing over across models
There are catastrophic, low-likelihood scenarios where the provider failover system is not enough. For example, in the extremely rare case that Google is down, our failovers for completions from Gemini would no longer work.
In these cases, we can also activate model failover: for each LLM API request, we can configure a different model to use in the event of failure.
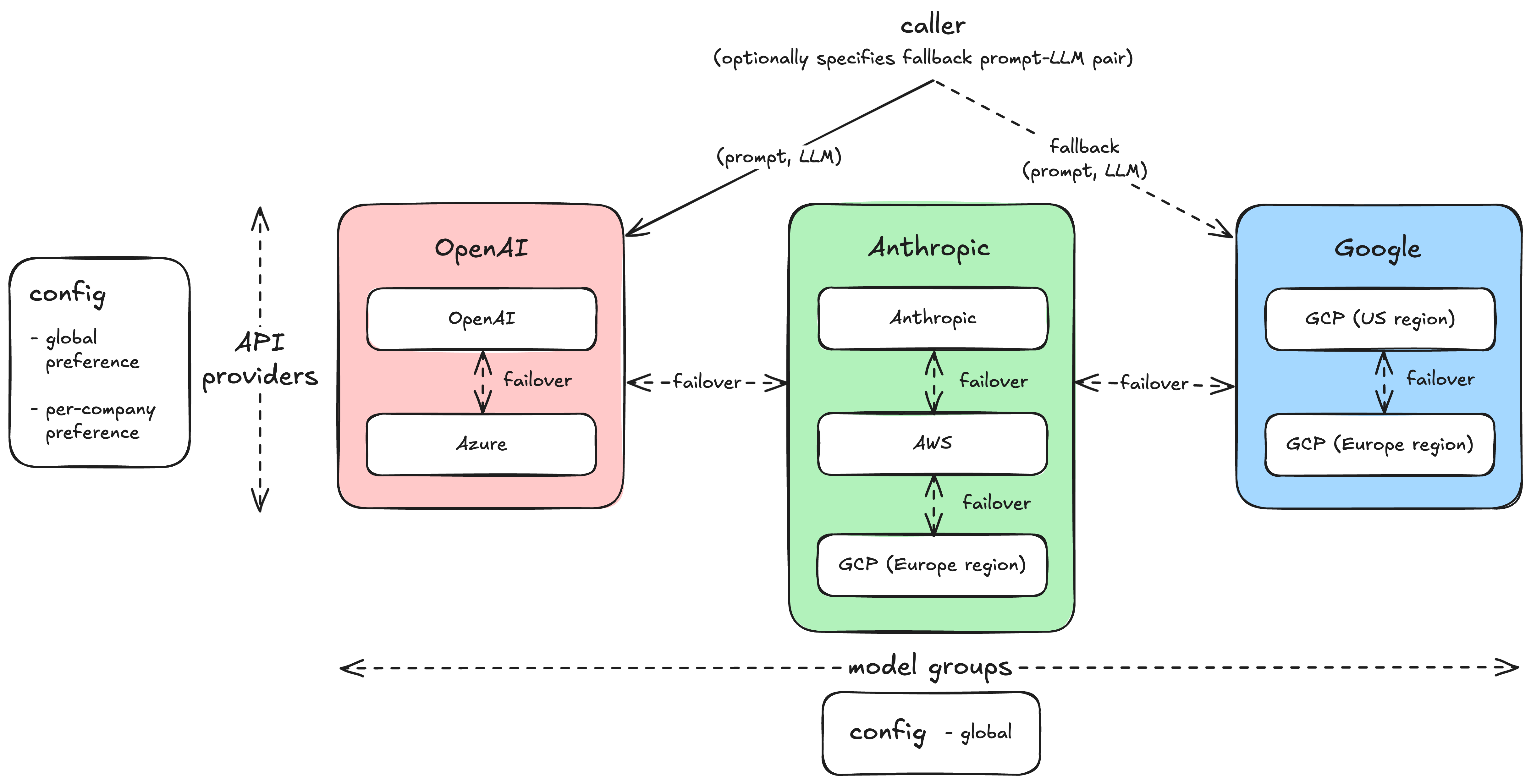
The main challenge of a model failover is that prompts that work well with one model don’t necessarily work well with others. However, designing and evaluating multiple prompt-model pairs for components of our agent is already part of our development lifecycle. For several critical components of our system, we have tailored prompts for both the primary and backup models.
This has a two-fold benefit:
In the event that the entire model group’s providers are down, our customers are protected, and their customers continue to receive replies from our AI agent.
In the event that we get rate-limited for newer and more experimental models, we can failover to older models for which we have higher rate limits.
Always improving
We’re always thinking about ways in which we can improve our resiliency—here is can a recent example. We’re already protected against scenarios where individual LLM API requests takes too long, because we time out and failover to the next provider. This timeout is designed to catch abnormally long requests — typically in the p99 percentile of latency. What should happen if the entire latency distribution shifts?
We observed this with one of our providers:
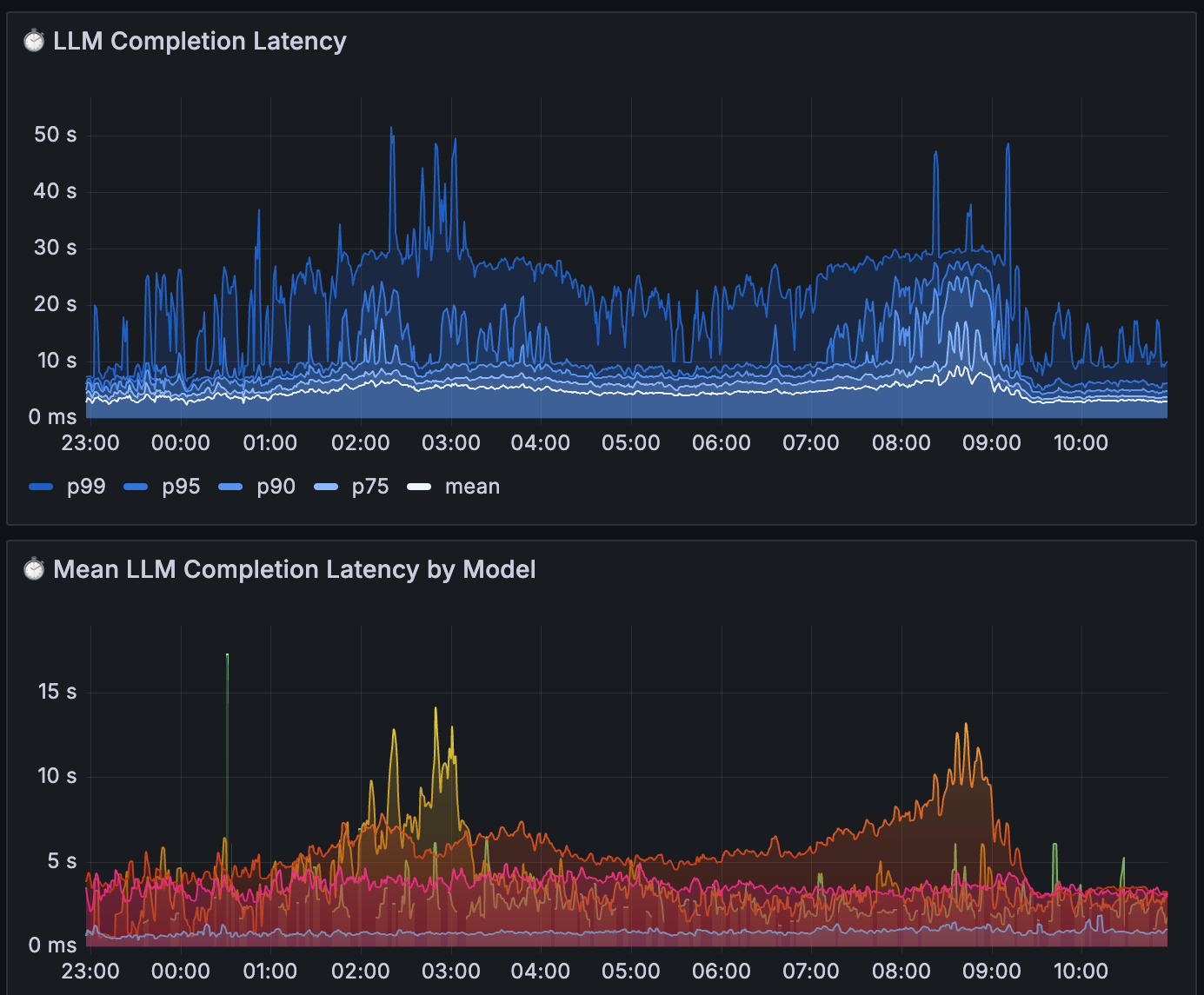
In this case, the mean latency of a few models spiked, and the p75+ latency jumped to well over 10s. This increased the overall latency of our agent, but didn’t initiate our failover mechanism. Thankfully, through our latency-based alerts, we were able to identify this fairly quickly and manually invoke the failover mechanism. However, this points to an interesting idea — can we auto-failover when we observe abnormal shifts in the latency distribution?
 | A guest post by
|
 | A guest post by
|
Nice article. Are you using any agent frameworks eg langgraph ? My impression is that you’ve built your own framework from the ground up to give you this flexibility to swap in api endpoints mid stream.